
12.12.2023 | Kuvittele ChatGPT:n kaltainen tekoälysovellus, joka ei ainoastaan vastaa yleismaallisiin kysymyksiin, vaan osaa myös luoda räätälöityä sisältöä yrityksesi erityistarpeisiin – hyödyntäen yrityksesi uniikkia dataa oppimisen ja sisällön tuottamisen lähteenä. Tämä on jo mahdollista nykyaikaisen tekoälyteknologian ansiosta. Tekoälyasiantuntijamme Samuli Reinikainen kertoo, miten yrityksen omaa dataa hyödyntävä generatiivinen tekoälysovellus on fiksuinta rakentaa, esittelee kolme esimerkkiä sen käyttömahdollisuuksista ja selittää, miten Efima voi olla ratkaisun käyttöönotossa avuksi.
Generatiivisen tekoälyn potentiaali erilaisissa tehtävissä on tullut selväksi viimeistään ChatGPT:n julkaisun myötä. ChatGPT perustuu GPT-nimiseen kielimalliin, joka on koulutettu valtavalla määrällä internetistä kerättyä tekstiaineistoa, jonka sisältö ja laatu on vaihtelevaa. Tämän koulutusprosessin ansiosta kielimalli on kehittynyt kielellisesti taitavaksi ja oppinut paljon yleistä tietoa maailmasta. Kielimallia voidaan hyödyntää monenlaisiin käyttötarkoituksiin: se voi esimerkiksi muokata, formatoida ja kääntää tekstejä sekä vastata geneerisiin kysymyksiin.
Nämäkin ovat jo hyödyllisiä ominaisuuksia, mutta entä jos haluaisit kysyä GPT:ltä kysymyksen vaikkapa omiin työsuhde-etuihisi liittyen? Tai jos haluaisit saada tekoälyn vastaamaan asiakkaan kyselyihin hyödyntämällä yrityksesi omaa tuotedataa? Tällöin tarvitset tekoälysovelluksen, joka osaa hyödyntää myös yrityksen omaa tietoa päättelynsä ja vastauksiensa pohjalla. Voisikin sanoa, että generatiivisen tekoälyn todellinen potentiaali liiketoiminnassa piilee siinä, miten se saadaan hyödyntämään internetistä peräisin olevan tiedon lisäksi yrityksen uniikkia liiketoimintadataa.
Miten luoda tekoälysovellus, joka hyödyntää yrityksen omaa dataa?
Yrityskohtaista dataa hyödyntävän tekoälysovelluksen rakentamiseen on muutamakin eri lähestymistapa, joista yksi on ylitse muiden. Kuvitellaan, että haluaisit luoda generatiivisen tekoälysovelluksen, joka vastaa työntekijöidesi kysymyksiin yrityksesi SharePointista löytyvien tietojen perusteella. Yksi vaihtoehto voisi olla, että jatkokoulutamme kielimallia näyttämällä sille koko SharePointin sisällön, jolloin malli oppii käyttämään myös tätä tietoa tietolähteenään – aiemmin internetistä oppimansa tiedon lisäksi. Tämä ei kuitenkaan ole kovin tehokas tapa, sillä suurten kielimallien kouluttaminen on laskennallisesti raskasta ja mallin muistiin tallentunut tieto on luonteeltaan epävarmaa. Emme esimerkiksi voi olla varmoja, vastaako jatkokoulutettu tekoäly kysymykseen internetistä vai Sharepointista saamansa tiedon perusteella.
Toinen vaihtoehto voisi olla, että annamme kielimallille koko SharePointin sisällön tekstimuodossa ja kysymme sen jälkeen tekoälyltä jotain esimerkiksi työsuhde-etuihin liittyen. Tämä ratkaisu voisi toimia, jos hyödynnettävää tietoa ei ole paljon. Mallit eivät kuitenkaan toimintaperiaatteensa takia pysty käsittelemään kerralla loputonta määrää tietoa – uusimmat mallit voivat tällä hetkellä hyödyntää enintään kymmeniä tuhansia sanoja suomen kieltä. Tämä tapa ei ole myöskään laskennallisesti järkevä, sillä malli joutuu prosessoimaan kaiken tiedon uudelleen jokaisen kysymyksen kohdalla.
Edellisiä tapoja parempi ratkaisu on antaa tekoälylle kerrallaan käsiteltäväksi vain se tieto, joka on olennaista kysymyksen vastaamiseksi. Tämä tarkoittaa sitä, että emme yritä jatkokouluttaa kielimallia kaikella SharePointin datalla, emmekä myöskään anna sille koko SharePointin datamäärää joka kerta, kun kysymme siltä jotain. Sen sijaan käytämme hakukonetta, joka etsii SharePointin datan joukosta ne tiedot, jotka liittyvät kysymyksen aiheeseen.
SharePointiin on sisäänrakennettu hakukone, jota tekoäly voisi periaatteessa hyödyntää sellaisenaan. Käytännössä, kun tekoälylle esitetään kysymys, tekoäly tunnistaa kysymyksen aiheen, luo sen perusteella hakukyselyitä ja hakee SharePointin hakutoiminnolla relevantit sivut kysymykseen. Tämä menetelmä, jossa generatiivinen tekoälymalli yhdistetään hakukoneeseen, on nimeltään RAG (Retrieval Augmented Generation). Se on laskennallisesti tehokkain ja järkevin tapa rakentaa tekoälysovellus, joka osaa käyttää yrityksen omaa dataa.
RAG-menetelmän etuja ovat:
- Se säästää laskentaresursseja, sillä tekoäly käsittelee vain ja ainoastaan kysymyksen kannalta relevanttia dataa tietolähteenään, eikä läpikäy kaikkea saatavilla olevaa dataa.
- Se parantaa vastausten laatua ja luotettavuutta, sillä kielimalli hakee aina tuoreimman ja relevantimman tiedon kysymyksen aiheesta.
- Se mahdollistaa monipuolisten ja dynaamisten tietolähteiden käytön, sillä hakukone voidaan konfiguroida hakemaan tietoa mistä tahansa yrityksen datavarastosta, rajapinnasta tai tietokannasta. Näitä voisivat SharePoint-esimerkissä olla vaikkapa HR- tai palkkajärjestelmän rajapinnat ja tietokannat.
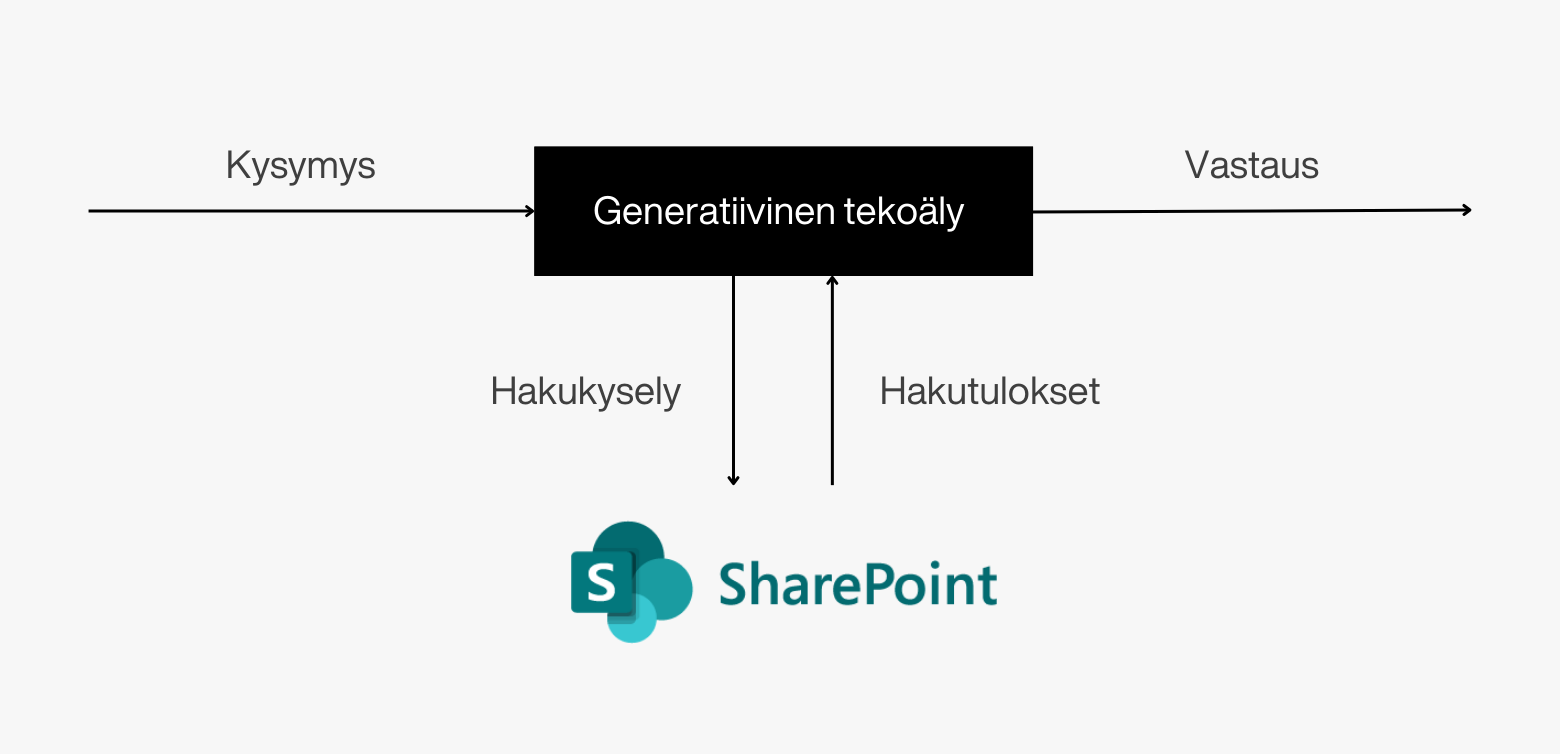
RAG-pohjaisessa tekoälysovelluksessa generatiivinen tekoäly hyödyntää hakukonetta hakeakseen relevanttia dataa ja tuottaa sisältöä hakutulosten perusteella.
Kuvailemassani esimerkissä tekoäly hyödyntää SharePointin olemassa olevaa, ihmisille suunniteltua hakutyökalua. Valmis hakutyökalu ei kuitenkaan ole ehto tekoälyn hyödyntämiselle, vaan tehokas hakutoiminnallisuus voidaan luoda tekoälysovelluksen kehittämisen yhteydessä. Tekoälykumppani voi siis rakentaa juuri käyttökohteeseen sopivan, useita tietolähteitä hyödyntävän hakukoneen puolestasi. Niin sanottu semanttinen haku on toimivaksi todettu ja suosittu tapa toteuttaa ei-rakenteellista tiedonhakua. Tällöin tekoälysovellukseen generatiivisen tekoälymallin rinnalle valjastetaan erillinen semanttista hakua toteuttava tekoälymalli etsimään relevantit materiaalit. Tähän aiheeseen paneudun tarkemmin seuraavassa blogissani.
Muita käytännön sovelluskohteita
SharePoint-tekoälysovellus on vain yksi – ja hyvin yksinkertainen – esimerkki siitä, miltä yrityskohtaista dataa hyödyntävä tekoälysovellus voisi näyttää. Todellisuudessa käyttökohteita on lukuisia, ja seuraavaksi avaan niistä kaksi:
Asiakaspalvelu
Asiakaspalvelussa omaan dataan kytketty generatiivinen tekoälysovellus voi tuoda merkittäviä hyötyjä. Kuvitellaan tilanne, jossa suuri osa asiakaspalveluun saapuvista palvelupyynnöistä on yksinkertaisia pyyntöjä, joihin vastaaminen vaatii asiakaspalvelijalta eri järjestelmistä ja vaikkapa tuotesivuilta löytyvän tiedon hakemista ja yhdistelemistä. GPT-kielimalli on suhteellisen helppo valjastaa luomaan geneerisiä vastauksia tai auttamaan asiakaspalvelijaa tekstin kirjoittamisessa ja muotoilemisessa. Mutta jos käyttöön valjastetaan RAG-järjestelmä, joka tunnistaa palvelupyynnössä esiintyvän tarpeen ja hakee tietoa järjestelmistä ja tuotesivuilta asiakaspalvelijan puolesta, koko asiakaspalveluprosessi saadaan automatisoitua lähes täysin.
Tällöin asiakaspalvelijan vastuulle jää (etenkin alkuvaiheessa) vain vastauksen validointi ja loppuajan hän voi käyttää vaativampien palvelupyyntöjen ratkomiseen. Samantyylistä järjestelmää voidaan hyödyntää myös puhelinasiakaspalvelussa, jolloin tekoäly voi hoitaa tiedonhaun asiakaspalvelijan keskittyessä olennaiseen.
Sopimustenhallinta
Toinen mielenkiintoinen käyttötapaus löytyy sopimustenhallinnasta. Yrityksen sopimusdokumentteihin rakennettu semanttinen hakujärjestelmä yhdistettynä generatiiviseen tekoälyyn voi nopeuttaa esimerkiksi tiettyihin ehtoihin tai lausekkeisiin liittyvien kohtien hakemista ja tunnistamista suuresta sopimusmassasta. Tämä mahdollistaa vaikkapa eri sopimuksissa esiintyvien hinnankorotusehtojen vertailun keskenään ja mahdollisten ongelmien tai ristiriitojen etsimisen sopimuksesta ja sen liitteistä. Tekoäly voidaan valjastaa myös tekstimuotoisten sopimusten muuttamisen rakenteelliseen muotoon, mikä mahdollistaa monenlaisia lisäautomaatioita.
Yrityksen omaa dataa hyödyntävät tekoälysovellukset ovat jo tätä päivää
Mainitut käyttötapaukset eivät ole enää vain tulevaisuuden visioita, vaan tällä hetkellä täysin toteutettavissa olevia ratkaisuja, jotka voivat tuoda merkittäviä hyötyjä liiketoimintaan. Efiman tekoälykehityksen tuloksena syntyneen tekoälypalvelun Efima tekstiÄlyn avulla saat omaa dataasi hyödyntävän generatiivisen tekoälysovelluksen turvallisesti käyttöön omassa organisaatiossasi. Efima tekstiÄly on pilvipohjainen tekoälypalvelu, joka automatisoi erilaisia tekstin pohjalta tehtäviä päättely-, haku- ja tekstinluomistehtäviä. Se hyödyntää sekä Efiman omia tekoälymalleja että ulkoisten tarjoajien suuria kielimalleja ja toimii erityisen hyvin suomenkieliselle tekstille – erottaen sen monista kilpailevista vaihtoehtoista.
Asiakkaan näkökulmasta tärkeintä on tunnistaa hyödyntämiskohteita, joissa:
- ihmisen suorittamaan manuaaliseen tiedonhakuun kuluu turhan paljon aikaa.
- tekoälyn vastaukset geneerisen internet-tiedon pohjalta eivät ole riittävän laadukkaita.
- prosessin kannalta olennainen tietämys ja liiketoimintadata on saatavissa rakenteellisessa muodossa tai tekstinä.
Tämä on ensimmäinen osa yrityskohtaista dataa hyödyntävien generatiivisten tekoälysovelluksien mahdollisuuksia ja toimintaperiaatteita käsittelevästä blogisarjasta, jonka on kirjoittanut Efiman tekoälyasiantuntija Samuli Reinikainen. Blogisarjan toisessa osassa Samuli kertoo, miten semanttinen haku ja generatiivinen tekoäly yhdistetään RAG-sovelluksissa ja mitä vaatimuksia RAG-sovelluksen luominen asettaa yritykselle ja sen datalle.
Tekoälysovellus teillekin?
Haluatko rakentaa älykkään RAG-sovelluksen, jonka avulla asiakkaasi tai työntekijäsi voivat saada nopeasti vastauksia liiketoimintaasi liittyviin kysymyksiin? Ota yhteyttä asiantuntijoihimme, ja viedään visiotasi yhdessä eteenpäin.
